소개
remark는 markdown을 처리하는 파서 및 생성기 입니다.
markdown을 처리할 수 있는 라이브러리는 많이 있습니다.
특별히 markdown-it과 marked는 매우 오랜 시간 주목을 받아왔고 사용처도 늘어나고 있습니다.
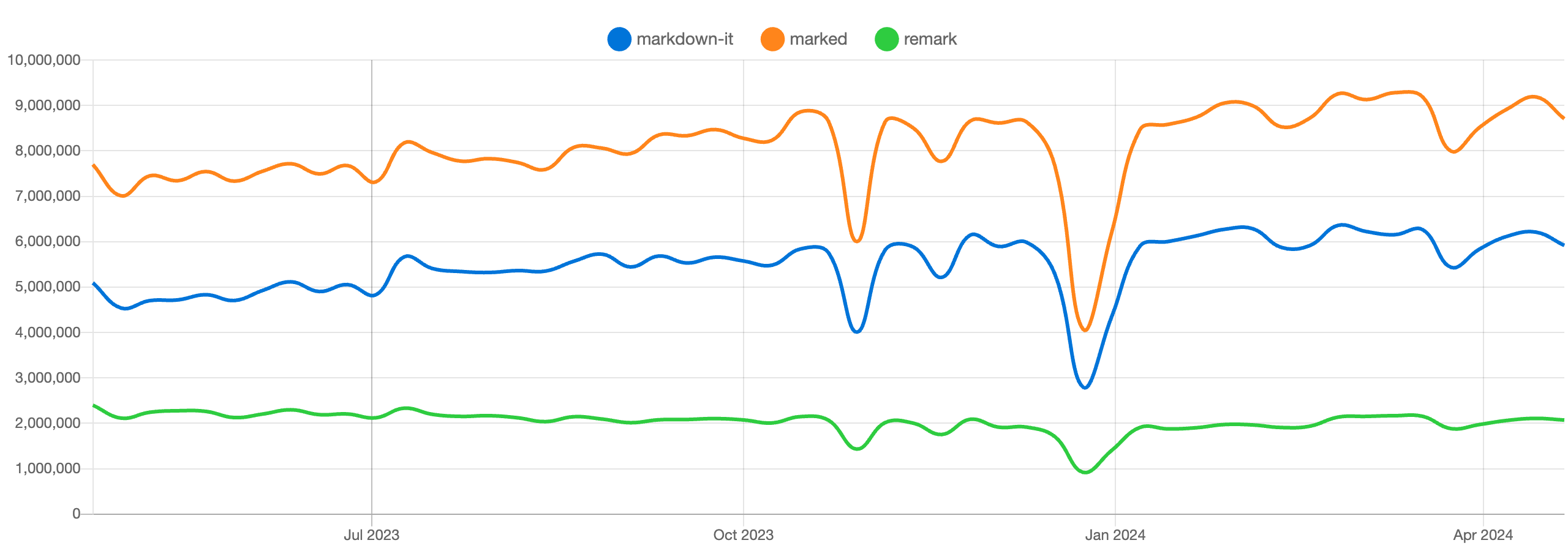 https://npmtrends.com/markdown-it-vs-marked-vs-remark
https://npmtrends.com/markdown-it-vs-marked-vs-remark
그럼에도 불구하고 remark에 주목을 해야 하는 이유는 mdx 툴체인의 코어 라이브러리이기 때문입니다. 사양을 주도하고 에코시스템을 만들어가는 주요 개발자들이 다음과 같이 유사합니다.
- https://github.com/orgs/unifiedjs/people
- https://github.com/orgs/remarkjs/people
- https://github.com/orgs/mdx-js/people
unified라는 패키지는 general purpose parser/generator를 표방합니다.
그 위에 remark가 markdown 파일을 처리하는 핵심 라이브러리와 플러그인 구조를 제공합니다. 다시 그 위에 MDX라는 markdown과 jsx를 결합한 형식을 제공하고 있습니다.
지금 이 글을 작성하는 방식도 mdx이고 Markdown and MDX와 같이 next.js에서 또는 MDX • Storybook docs와 같이 storybook에서도 사용할 수 있는 보편적인 형식이 되었습니다.
MDX 처리에 있어 핵심이 되는 플러그인 구조를 제공하는 remark를 이해하는 것은 에코시스템의 활용과 확장의 측면에서 의미가 있을 것이라 생각합니다.
기술 스택
tsconfig.json을 사용하지만 ts 파일 대신 js 파일에서 주석을 기반으로 형검사를 수행합니다.
다음은 remark의 의존 관계 다이어그램 입니다.

unified 패키지를 기반으로 micromark 패키지군을 사용하여 mdx 파일을 파싱하고 mdast-util-to-markdown 패키지를 사용하여 파싱한 결과인 markdown ast 정보를 바탕으로 html을 생성합니다.
remark는 다음과 같이 단 한줄의 코드로되어 있습니다.
// Note: types exposed from `index.d.ts`
import remarkParse from 'remark-parse';
import remarkStringify from 'remark-stringify';
import { unified } from 'unified';
/**
* Create a new unified processor that already uses `remark-parse` and
* `remark-stringify`.
*/
export const remark = unified().use(remarkParse).use(remarkStringify).freeze();
물론 remark 소스코드는 monorepo로되어 있어 remark-parse, remark-stringify와 같은 패키지를 사용하여 AST를 만들고 다시 텍스트로 출력하는 일련의 코드가 존재 합니다.
위의 코드를 이해하려면 unified의 동작 방식을 이해할 필요가 있습니다.
unified()를 호출하는 리턴 값은 Processor라는 클래스의 인스턴스 입니다.
이 Processor는 use, freeze, process 등의 API를 제공합니다.
Processor는 다음과 같은 일종의 가상함수를 가집니다.
parser:string입력을 받아 tokenize한ParseTree를 반환합니다.remark-parse에 해당 구현이 있습니다.compiler:parser에서 전달한ParseTree를 바탕으로 새로운 형식으로 출력합니다.transformer:ParseTree를 전달 받아 이를 조작합니다.
정리하면 unified()의 call chain을 통해 parser, compiler, transformer를 조합할 수 있습니다.
이 후 process 함수를 호출하면 parer로 부터 ParseTree를 생성하여 transformer를 거쳐 compiler에 전달합니다.
처리과정
다음은 micromark 테스트 코드를 수행했을 때의 과정을 보여줍니다.

입력으로 전달받은 문자열을 tokenizing 합니다. token 정보는 이벤트 형식으로 전달합니다. token 이벤트를 기반으로 html을 생성합니다.
마치며
remark 스스로는 parse API를 통해 markdown의 AST를 생성하고 process API를 통해 다시 markdown을 생성하는 역할을 하는 간단한 라이브러리 입니다.
따라서 실제로 많이 사용하는 패턴은 remark-parse를 사용하여 Markdown AST를 생성하고 다양한 plugin을 조합하여 원하는 출력을 얻어내는 것 입니다.
대표적으로 mdx-js/mdx의 경우 remark-parse, remark-mdx, remark-rehype 등의 패키지를 조합하여 mdx 형식의 파일을 처리 합니다.
@mdx-js/react라는 패키지를 활용하면 @mdx-js/loader를 사용해 생성한 코드를 custom 컴포넌트와 함께 렌더링할 수 있습니다.
Markdown의 사용은 개발자 커뮤니티에서 부터 시작해서 다양한 분야로 퍼지고 있습니다.
많은 문서 형식들이 존재해 왔지만 결국에는 그 자체로 읽기가능하고 포팅이 쉬운 방식을 사람들이 선택하고 있습니다. 마치 xml을 json이 대체하 듯이 evernote, notion 등의 proprietary 포멧이 아닌 defacto 문서 형식으로 markdown을 사용하고 있습니다.
이런 markdown을 손쉽게 확장함으로서 유연성을 제공하는 mdx 형식과 그 생태계를 주목하고 관련 기술을 습득해 둠으로서 각자의 분야에서 새로운 아이디어를 이끌어내는 재료가 되리라 생각합니다.
개인적으로 unified의 생태계를 이해하고 분석하는 것이 쉽지는 않았습니다.
워낙 많은 패키지에 걸쳐 기능이 구현되어 있고 js에 주석기반의 type checking을 하는 코드를 이해하는데 시간이 필요했습니다.
함수형 기반으로 작성하다보니 higher order function이 많았고 이를 트레이스하고 분석하는 것 역시 지루하고 고된 작업이였습니다.
덕분에 포스팅 작성이 오래 걸렸지만 한편으로는 후련하네요. ㅎ